An Overview of the Components: PERL, Csound, and RealAudio
The Search and Retrieval Process
The PERL/Csound Initialization Process
The Csound Process
An Overview of the Components: PERL, Csound, and RealAudio
Bits and Pieces is a sound installation for the World Wide Web. Although its aesthetic precedents are numerous, its technical precedents are few. The primary new concept behind the piece is the use of audio sources from the Web. A group of computer programs search the Web for sound files, then download and process them. This process, which I call the ‘search and retrieval’ process (see Figure 1), is written in a programming language called PERL. The three major components used in Bits and Pieces are PERL, Csound, and RealAudio. The entire code for Bits and Pieces may be viewed in Appendix B.
PERL is an acronym for Practical Extraction and Reporting Language. Its primary uses are parsing and extracting data from other sources of data, scripting for Unix, and creating CGI scripts for Web pages. It is also useful as a networking language. The capabilities of the core PERL language can be expanded by the addition of modules that are readily available on the Web. Modules are PERL objects that contain functions specific to various needs. The modules used for Bits and Pieces contain functions for making network connections, downloading files, downloading web pages, and parsing text. There are also PERL scripts, such as AutoSearch, that can be called from a Unix shell environment to query search engines regarding a topic. This script was used extensively in Bits and Pieces, but it will be discussed below.
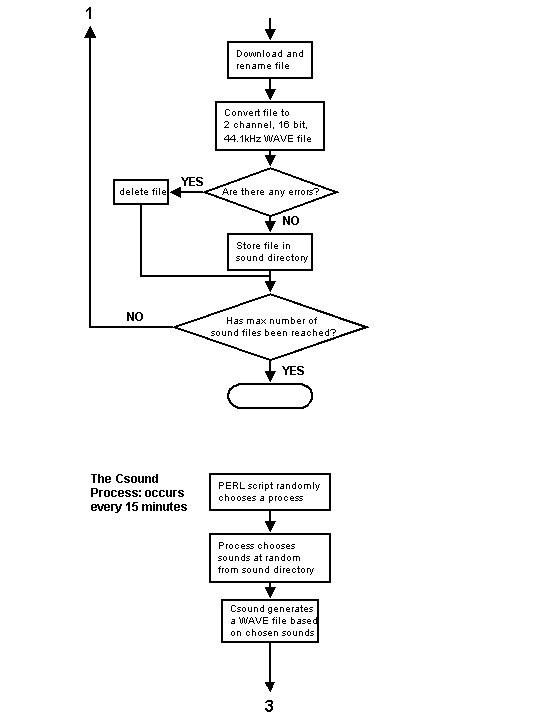
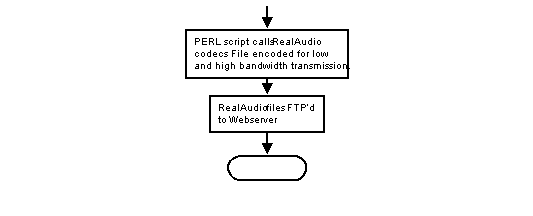
Figure 1. A flowchart overview of the three processes.
The second major component used in Bits and Pieces is Csound. Csound is a sound synthesis language whose source code is written in C. A Csound piece or process is written in two parts. The first part is an orchestra file in which instruments are defined. Csound instruments are user defined synthesis or sound processing routines. The score file tells the Csound compiler how and when to play the instruments in the orchestra file. It also contains function and wavetable definitions. For Bits and Pieces, PERL was used to generate the orchestra and score files for the Csound compiler. The output of a Csound process can either be played in realtime (depending on the speed of the computer), or written to a sound file. In this case, all Csound output was written to a sound file.
The final component used in the Bits and Pieces process is the RealAudio encoder. RealAudio is currently the most popular software tool for creating and streaming media over the Internet. It is used to stream both audio and video (although in my piece only audio), and can be optimized to stream at different qualities for different connection speeds. Presently, most Internet connections are far too slow to handle the (at least) 175 kilobyte per second transmission rate required to receive 16 bit 44.1K stereo audio. Thus, compression is usually used. A compression program is called a ‘codec,’ short for coder/decoder. The compression scheme used by RealAudio is based on psychoacoustic principles involving the masking of quieter frequencies by louder ones. RealAudio reduces a file's size by removing masked frequencies that the listener will theoretically not hear. For low bandwidth transmissions, a RealAudio codec can reduce a 50 megabyte file to under 1 megabyte. Of course, this results in a large reduction in the quality of the sound file. The Bits and Pieces output file is encoded twice, for two different connection speeds. The first encoding of the original file results in a RealAudio file suitable for transmission over a 28.8 kilobaud connection. Unfortunately, this results in a reduction of a stereo audio file to a mono file, as well as a significant reduction in sound quality in that a large number of frequencies are removed. The second encoding of the original file is for connections of 80 kilobaud or faster. The RealAudio output file for this compression scheme is seven to eight times larger, but the file is in stereo and the sound quality is markedly improved.
The Search and Retrieval Process
The Bits and Pieces installation is divided into two major stages. The first stage is used for the search and retrieval of sound files from the Web. The second stage is used for the processing of those sound files with Csound, the encoding of those files with RealAudio, and the transfer of the RealAudio files to the Webserver.
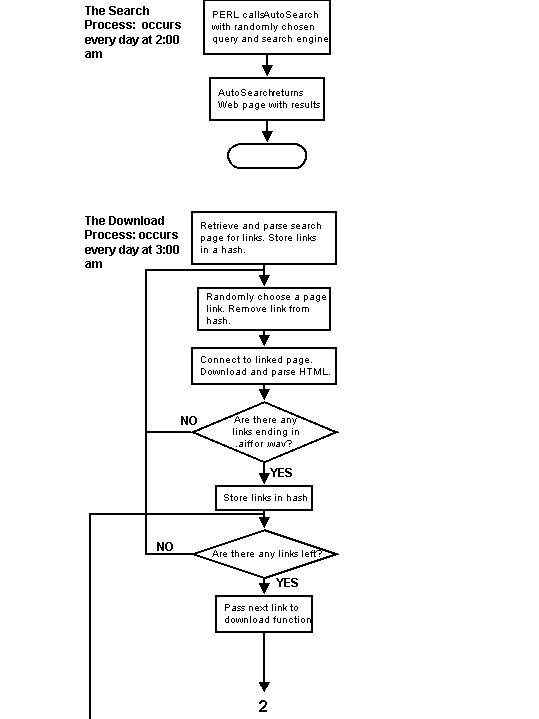
The search and retrieval section of the Bits and Pieces process is itself divided into smaller processes. PERL's AutoSearch script is a Web searching script that can be called from the Unix command line as well as from within a PERL program or script. Given the name of a major Internet search engine, a search query, and local directory as arguments, it returns an HTML (Hypertext Markup Language) page containing the results of the search. It places the page in the directory named in the function arguments.
The page returned typically contains hypertext links to between one hundred and two hundred Web sites that are possible matches to the query. This simplifies the Web searches, and leads to more immediate and accurate results for several reasons. Most major search engines are Web crawlers, that is they constantly search the Web for new sites and pages, simultaneously updating their databases. When a Web crawler accesses a page, it parses the HTML and attempts to determine the topic of the site by looking for keywords. It then adds that site to its database, and tries to categorize it based on the keywords. When a search engine is queried, it returns a list of possible matches sorted according to the probable accuracy of the match. Thus, the pages that are most likely the best match to the user’s query are listed first. What this means for my search and retrieval process is that AutoSearch will return links already sorted and categorized by the queried search engine. The results are further improved in that AutoSearch can query several different search engines (although not in the same run). This means that I have access to several different large databases of Web pages possibly containing sound files.
Because this installation runs on a Silicon Graphics computer using a Unix based operating system (Irix 6.2), it is possible to schedule the running of certain programs on a regular basis using the Unix cron command. The search and retrieval program is called by cron every day at three a.m. This time was chosen because it is a non-peak hour in the U.S. and network traffic is lighter. Thus, download speeds are generally faster.
When the search and retrieval process begins, the PERL script calls AutoSearch. The search engine and the query are randomly chosen from two arrays containing the names of search engines and query words respectively. The search engines currently used are AltaVista, Yahoo, Excite, WebCrawler, and NorthernLight. The queries currently used are ‘music,’ ‘music files’, ‘aiff,’ ‘aiff files,’ ‘sounds,’ ‘sound samples,’ ‘sound files,’ ‘wav files,’ and ‘wave files.’ This was done to achieve variety in the search results and a wider selection of available sound files. Once the Web page containing the search results is returned by AutoSearch, a PERL subroutine parses the page's HTML and extracts the hyperlinks. The hyperlinks are then stored in a hash table, an associative array in which data is retrieved through the use of keys, rather than numerical index. The resulting hash is passed to the parsing routine again. This time, however, the routine enters a loop. For each pass through the loop, a Web address is randomly removed from the hash. Randomly choosing Web addresses from the hash assures that the parsing routine, if given the same hash two or more times (i.e. if the search routine picks Yahoo search engine with "sound files" query two days in a row), won’t go through the resulting hash in the same order, and thus will ideally download different sound files on each run.
}
Figure 2. This function, in the downloading script, gets a Web page, and, depending on the parameter given to the function, saves all the links in a hash, or only links ending in .aiff and .wav.
The parsing routine contacts the given Web address and attempts to download the HTML from the Web page. If there is no response, the routine times out and the next address is tried. If there is a response, the page is downloaded, and the routine parses the HTML to look for links to sound files of type AIFF or WAV. It does this by looking at the hyperlinks on the page and performing pattern matching tests on those links. If the very last part of a hyperlink ends in ‘.aiff’ or ‘.wav’, it means that the hyperlink leads to a sound file of that type. If this is so, then the hyperlink is again saved to a hash. Once all the possible hyperlinks leading to sound files for a particular page are extracted, the hash containing them is passed to the downloading routine.
The downloading routine, much like the other routines, is also a loop that executes once for each sound file that it attempts to download. The routine is given a sound file address from the hash. It then parses the address to determine the name of the sound file. Based on how many sound files have been successfully downloaded, it creates a new name for the sound file that is a combination of the word "soundfile" and the file’s number. If the downloader retrieves 25 sound files successfully, then the names of the sound files will be "soundfile_1.wav" through "soundfile_25.wav." This naming method is used to facilitate the random selection of sound files for later processing by Csound.
The sound file address is then passed to a PERL script called lwp_download. This script, when given a Web address of a file, downloads the file into a local directory. This script has been modified not to accept files larger than five megabytes. This is due to the fact that most of the sound files found on the web are in low bit depth, low sample rate, and mono formats. In order to make it easy for Csound to treat all sound files equally, the files are converted to a common format using sfconvert, an Irix sound file conversion utility. Because of this, a five megabyte sound file that is in an 8-bit 11kHz mono format will be greatly increased in size once converted to a 16-bit 44.1 kHz stereo file. The resulting file may be too large for Csound and the host computer, since the sound files are loaded into RAM when processed in Csound. There is also the consideration of download time. If the search and retrieval program finds a 30 megabyte sound file, but can only download it at a rate of four kilobytes per second, it will take over two hours to download the file, and will cause a ‘traffic jam’ for the installation.
Upon a successful download, several actions are performed on the sound file. First, the sound file is converted to a 16 bit 44.1 kHz stereo WAVE file and renamed. A record is kept of any errors sfconvert encounters in this process. The file is then checked with Csound’s sndinfo utility. This utility returns information about the file type, size, etc. A bad WAVE file output by sfconvert cannot be read by Csound and thus would cause an error in the output and a subsequent ‘traffic jam’ in the process. These files, upon discovery of error, are automatically deleted. Once a sound file passes all the tests, it is moved to a special directory from which the sound production script will randomly choose and load files into Csound. When completed successfully, the search and retrieval process will have downloaded 25 sound files for the day. The remainder of the process is taken up by the sound production script.
The PERL/Csound Initialization Process
The sound production script is a PERL script that produces the Csound output, converts it to RealAudio, and transfers it to the proper directory on the Web server. The process begins with a chooser script that calls a random number function. The number chosen is used to pick from a number of available PERL generated Csound processes. The design of the chooser process is modular in that I can add standalone PERL generated Csound processes without having to alter any other code. The chosen PERL/Csound process then calls a random number function. The random numbers chosen are appended to the end of the word "soundfile" to form the names of the sound files that Csound will use. Once the names are chosen, and before Csound is run, the sndinfo utility is called on the sound files. As stated earlier, this utility returns information about the sound file.
In Csound, it is necessary to know the number of sample frames in a sound file in order to allocate the right amount of memory. A single sample frame of a stereo sound file is a pair of stereo samples. The output of sndinfo is parsed, the number of sample frames extracted, and PERL variables set to table sizes capable of storing the samples.
Primarily, the various processes deal with fragmentation of the source samples. The ways in which they fragment the samples differ. The Csound processes are varied, with one being randomly selected each time the chooser script is called. Although their output is different, they are generally based on a similar instrument design. They do, however, share some common aesthetic traits.
One Csound process reads through each file once over the duration of the piece. As it reads through each file, it randomly selects one file's output for each event (an event being the playback of a fragment of sound). The events, also referred to as notes, occur at random points with random durations within a set of parameters. As the parameters change through the piece, the average spacing and duration of the notes changes. Several envelope shapes are also randomly chosen for each note, giving some notes sharp attacks and exponential decays, and others the opposite. The parameters for pitch shifting also change throughout the pieces, so that the samples get shifted to increasingly higher and lower pitches as the piece progresses.
Another process is a variation on the above instrument in which the random occurrences of notes gradually move toward a steady pulse and then back toward randomness. The notes are increasingly comb filtered toward the end of the piece. The frequency responses of the filters are randomly selected within given parameters for each note. Thus, the piece begins with discernable chunks of sound samples that are eventually transformed into pitched notes with little resemblance to their original source.
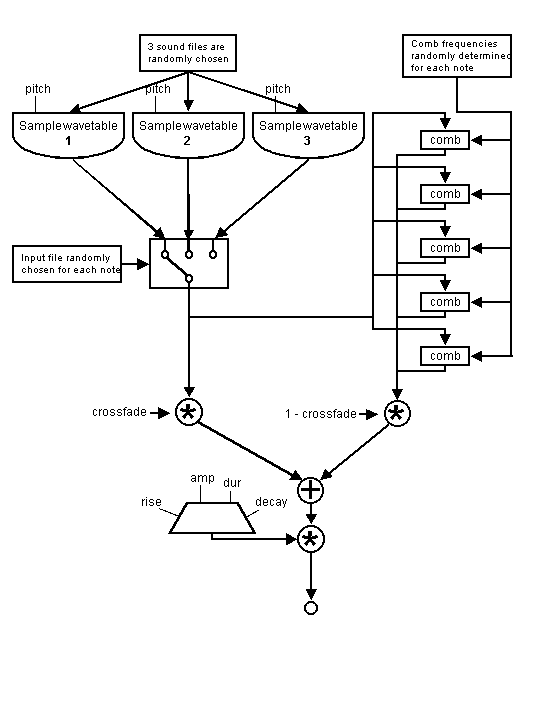
Figure 3. A synthesis flowchart of a typical instrument design used in Bits and Pieces.
The output of all the Csound processes is a WAVE file. Once a Csound process is complete, the WAVE file is encoded twice with RealAudio and FTP'd to the Webserver. Once on the Webserver, the files are linked to from a special text file called a ‘ram’ file. The ram file contains a list of links to the ten most recent Bits and Pieces RealAudio files on the server. When a new RealAudio file is FTP’d to the server, a new ram file is written listing that file as the most recent. When a user clicks on a link to hear Bits and Pieces, their RealAudio player receives a ram file giving it the links to the ten most recent RealAudio files in the order of newest to oldest. Thus, two users who begin listening to Bits and Pieces 15 minutes apart will receive different ram files and thus have different listening experiences.